sense word corpus disambiguation training senses semantic words data lexical context evaluation wsd results model task proceedings tag al
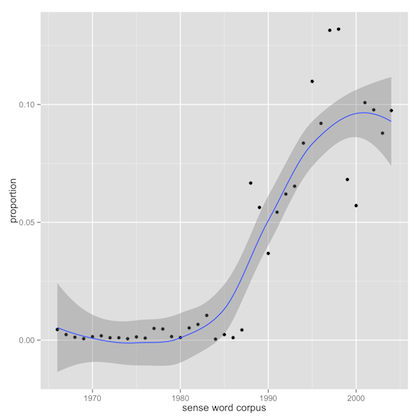
sense word corpus disambiguation training senses semantic words data lexical context evaluation wsd results model task proceedings tag al